Technical Overview¶
Ghostferry is a Go library to move data from one MySQL instance to another while the source (and possibly the target) databases are online. In order to do this, Ghostferry must be able to copy the data from a source database to a target database while keeping track of all changes in the source database to apply them to the target database. This is implemented by SELECTing from the source database and INSERTing them into the target (copy) and applying the binlog changes from the source on the target (change synchronization).
This setup has the advantage of working with essentially any configuration of MySQL. It also provides a seamless process as it is all contained in a single package, as opposed to split between multiple applications (mysqldump/xtrabackup and MySQL replication).
It is important to note that Ghostferry is simply a part of the puzzle of a live database migration. For data integrity reasons, Ghostferry mandates that you stop writes to the dataset you are copying at a stage of execution called cutover. During the same stage of execution, you’ll also likely need to instruct any applications accessing the source database to access the target database instead.
To gain a better understanding of the overall process, let’s take a look how Ghostferry works:
- Ghostferry begins to pull binlog events from the source database, applying the entries that are applicable to the target. This continues in the background.
- Ghostferry SELECTs data from the source database and INSERTs them to the target database.
- Ghostferry finishes copying all data from the source and target database. The binlog apply operation of (1) continues in the background.
- Ghostferry waits until the binlog apply is close to caught up to the latest available position on the source database. This is done so we don’t initiate the cutover process when there is a large backlog of binlog entries to be applied to the target, thereby reducing the downtime required.
- Outside of Ghostferry: you should allow no more writes to the source database via either a read_only flag (for whole database copies) or some sort of application level lock (for partial database copies).
- Instruct Ghostferry to enter the cutover phase. This essentially tells Ghostferry to stop tailing the binlog after catching up to the latest master position. Once Ghostferry does this, it terminates. This step can be done via the web UI or via a method call.
- Outside of Ghostferry: you should change the application that uses the source database to use the target database. You should also enable writes on the target database if it was previously read only somehow.
This process has some downtime between step 5 and step 7. The window of downtime is proportional to how fast these steps can be done. In most cases this should be on the order of seconds to minutes.
Architecture¶
Ghostferry has three levels of public APIs that you can use: the Ferry level, the DataIterator/BinlogStreamer level, and the Cursor level. Most of the time you only need to call methods on the Ferry. The other two levels only come in handy when you want to implement an alternative Ferry and alternative verifiers.
There are several auxiliary components to the system: the throttlers, the verifiers, the control server. These components are optional to Ghostferry runs.
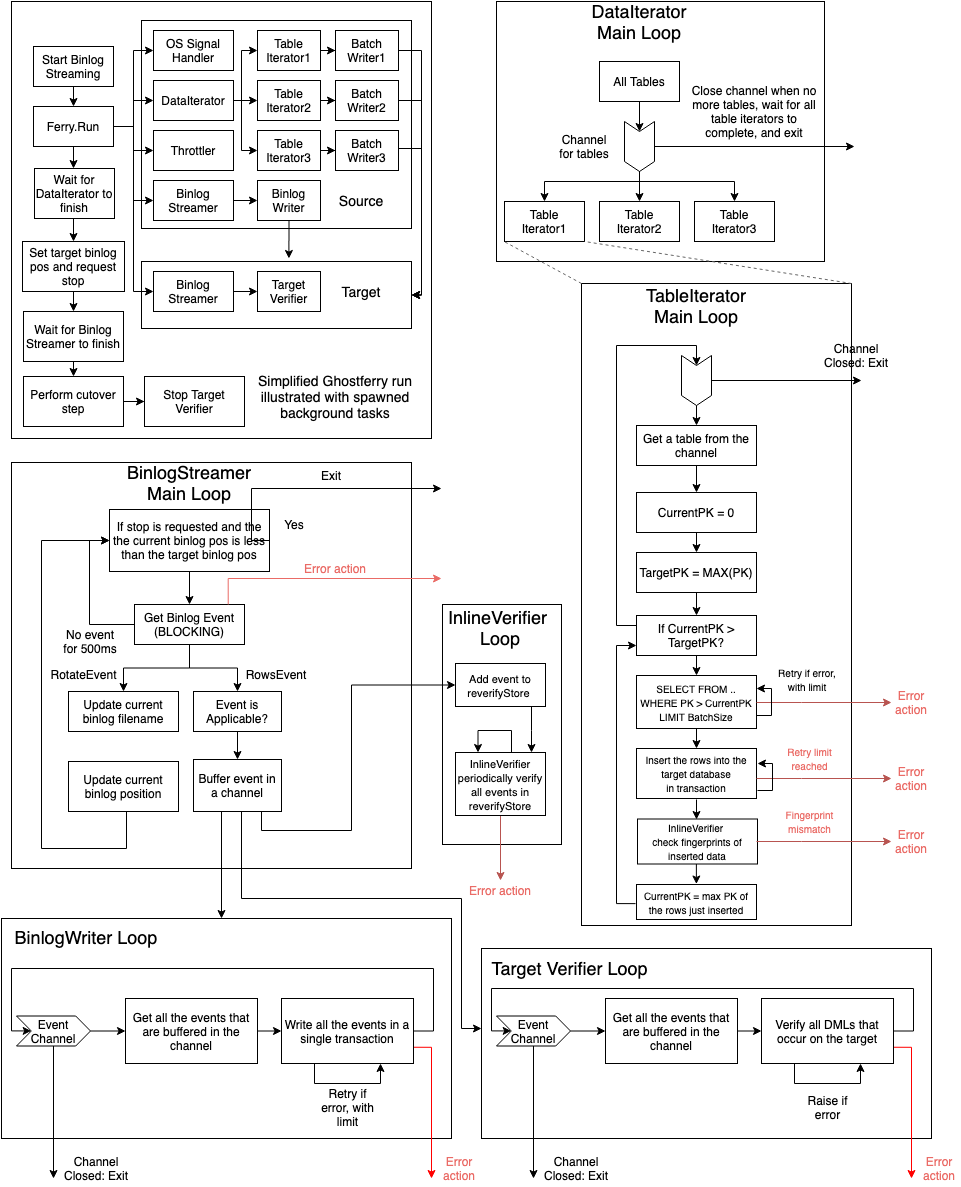
The overall, simplified architecture of Ghostferry can be summarized with the
figure below. It shows the basic flow of all the background tasks, along with
how each task is spawned (starting from Ferry.Run). Arrows pointing towards
outside of an encapsulating box indicate the task will exit. The red arrows
with “Error action” indicates an error has occurred and the error is sent to
the ErrorHandler, at which point the ErrorHandler flow takes over.
You can see an example of an application built with Ghostferry in the
copydb package.
Limitations¶
- Right now, Ghostferry can only be used on tables with auto incrementing,
numeric, and unique primary keys.
- An error will be emitted during the beginning of the run if such a primary key is not detected.
- In the near future, we will extend support to arbitrary primary key types.
- To work around these restrictions, you can use mysqldump to dump and restore the table during the cutover.
- Ghostferry can only be used on a source database with FULL RBR.
- An error will be emitted during the beginning of the run if FULL RBR is An error will be emitted during the beginning of the run if FULL RBR is not enabled on the source database.
- Without FULL RBR, the integrity of the data cannot be guaranteed.
- Ghostferry does not support tables with foreign key constraints.
- For tables with foreign key constraints, the constraints should be removed before performing the data migration.
Algorithm Correctness¶
The overall algorithm of Ghostferry is specified in a TLA+ specification and
validated via TLC. The algorithm can be see in the tlaplus directory in the
source tree.