
Stable Diffusion, a latent text-to-image diffusion model AI, was released in August, joining existing image models like MidJourney and Dall-E 2 in offering jaw-dropping image-making powers to even the most untrained of artists. Human creativity has always been the primary driver of commerce and these AI tools have unlocked enormous economic potential.
Stable Diffusion is open-source. Anyone who wishes to install and run it like software locally on their computer can do so. They can also use the images it creates freely in any application, including commercial ones. The impact on commerce can’t be understated.
Consider one particular use case: shopping for wallpaper is hard when you have something specific in mind but don’t know where to find it. If your search fails, just ask Stable Diffusion to create it and have it produced on-demand.
We wanted to take this idea a step further to see if we could conjure a genie!
Wallpaper Genie
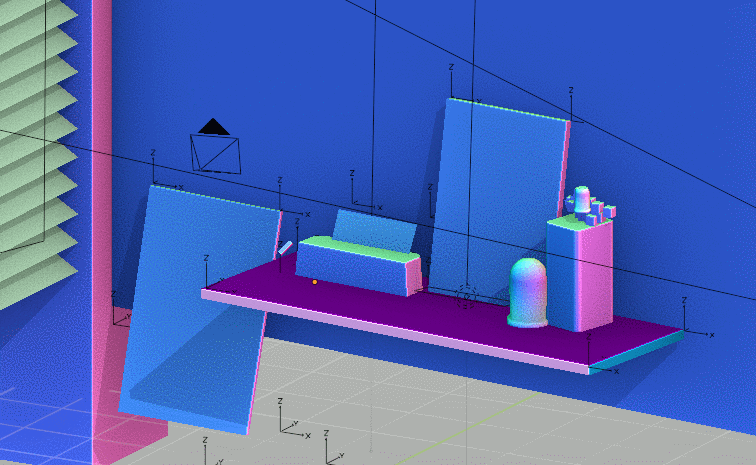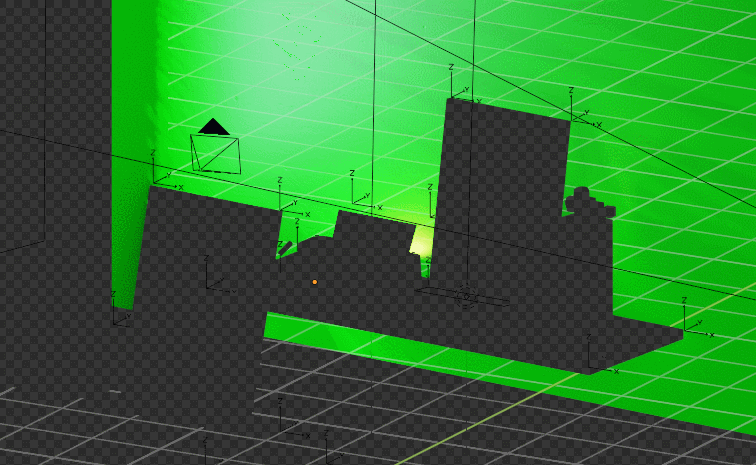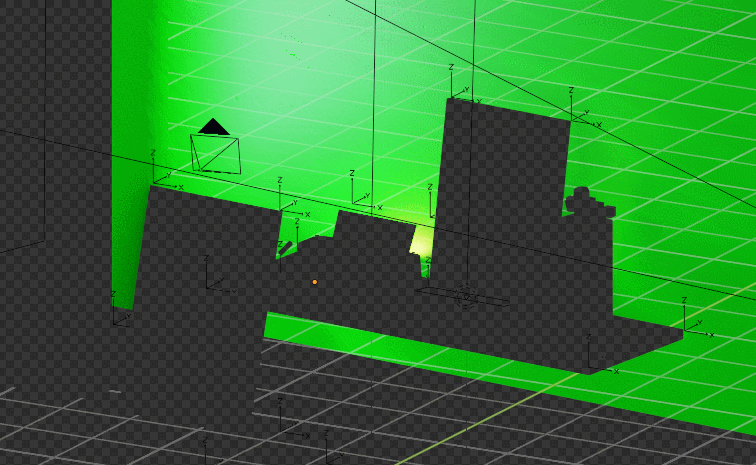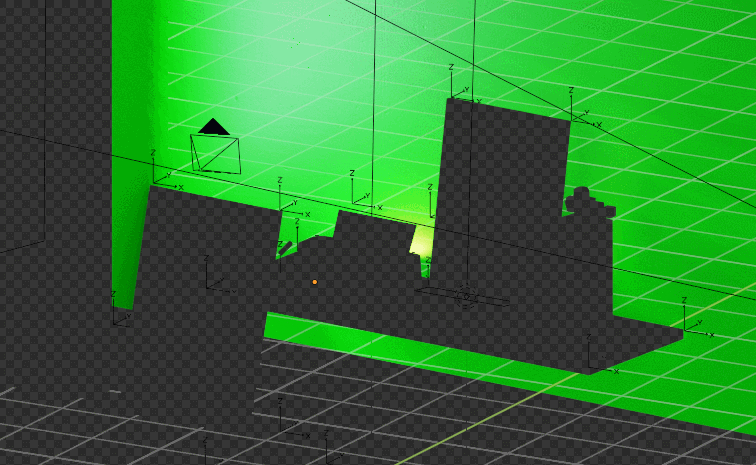
Wallpaper Genie makes it easy to conjure and buy any wallcovering you can imagine. Open the app and ask for something specific. Genie will conjure it right onto your walls in real time with AR.
Not quite satisfied with the look? Ask Genie for a change. Your wish is its command-line!
Buy what you love instantly. It knows just how much you need to cover that wall. On-demand printing and fulfillment gets it to your door in 5-7 business days.
“Say hello to the AI Product Genie. Your wish is its command-line.”
How we made it
Although we created the video in Blender to stay atop the blistering pace of innovation in this space, we conceived and designed the concept with today’s APIs and device capabilities in mind. This is a project that could entirely work today if you were patient enough to wait for the AI imagery to be generated, which currently takes ~10 seconds on a desktop GPU and longer on mobile devices. But! That time is decreasing every week and month, so we felt honest about representing this as an idea very soon to become practical.
The other caveat is the idea that an AI genie could deliver exactly what you have in mind on the first try. In reality, we ran hundreds of requests through Stable Diffusion, endlessly tweaking variables and inputs to generate thousands of potential image steps we could then cherry pick from to get exactly what we wanted.



One big prototyping unlock we discovered recently was an iOS app called CamtrackAR which records the device accelerometer and tracks spatial anchor data alongside recording video, so the files it exports can easily be brought into Blender as fully fledged video “tracking” shots, which eliminates the often tedious process of visually tracking video from just RGB image data.
The transitions between two given still images was done with DAIN, another AI system. We diffused each frame of the morph animation using the img2img feature with a low variance setting. This subtly remakes each frame as a complete “vision” unto itself, giving the illusion that Stable Diffusion is dreaming every frame of the transition. We did this manually, but this is a pipeline that could also be built in the cloud.
So in the end we made a 2D video of the whole runtime that has all the stills, transitions and timing that the voiceover script demanded, and then that’s just inserted into the 3D scene as a video texture on a big plane that matches the wall. Add some clipping geometry for the objects in front of the wall to cut them out, and you basically have a complete VFX shot with just that.
With that combined render in hand and working, we added a UX layer: the orb and the text overlay.
This wasn’t wildly novel, we’ve seen these types of designs and paradigms everywhere with Siri and similar assistants, but that familiarity was intentional to ground it a bit.
We originally had the orb in world space, so it floated around you like a character or drone might, but it felt distracting and chaotic, so we eventually settled on a screen-space version that just sits at the bottom like you might see camera UI buttons or similar.
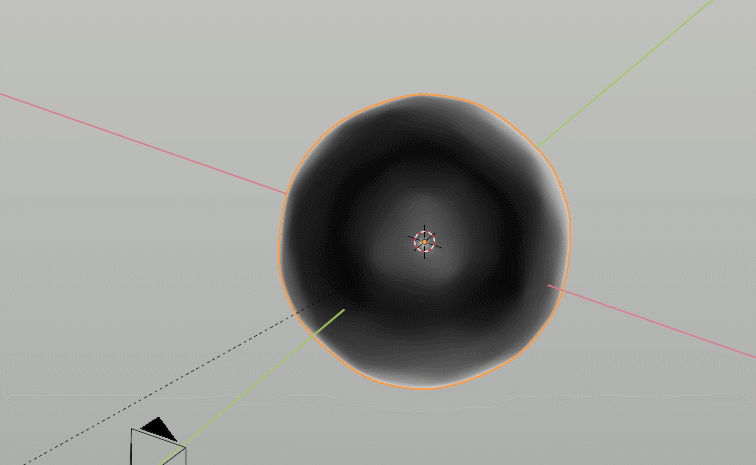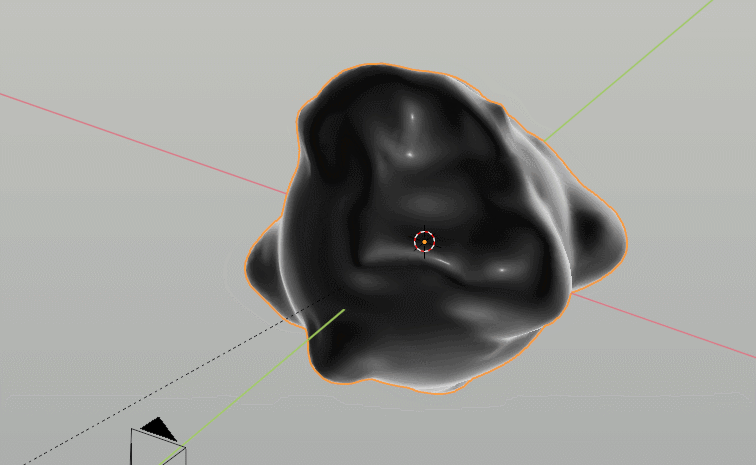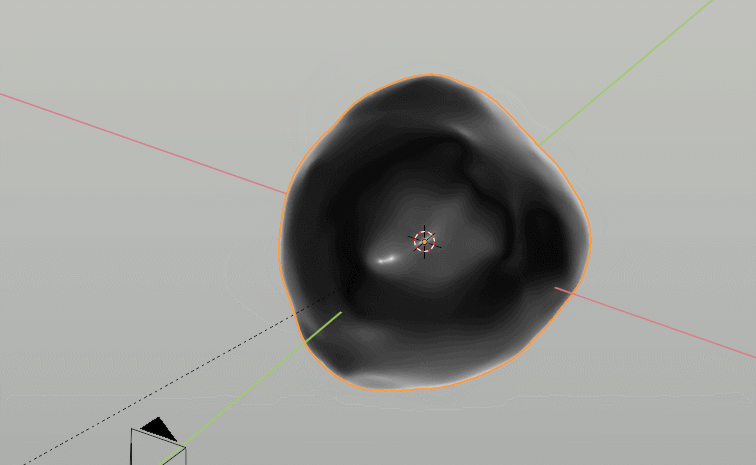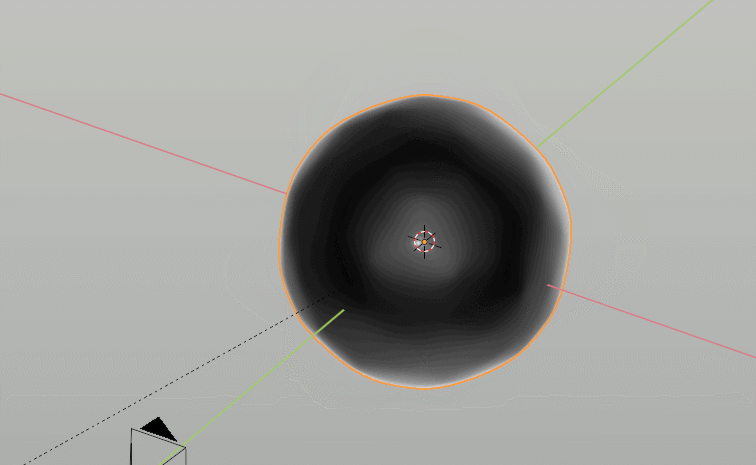
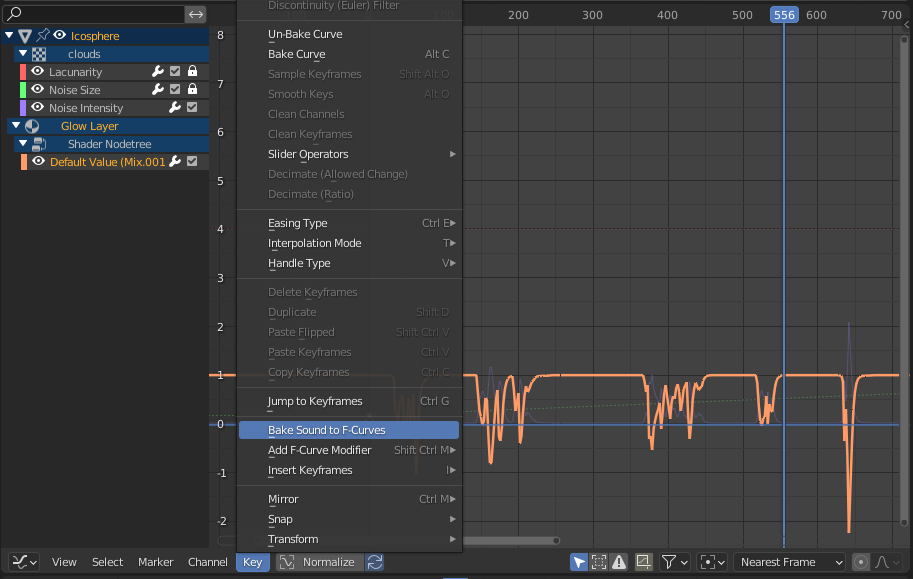
One small fun thing to point out is that Blender actually just has a built in sound-to-curves button that automatically takes MP3 files and adds them to whichever curve you want, so in this case we drove some emission for the white lighting and displacement of a basic sphere mesh merely by cutting up the voiceover in the video to be the sound file with just the activation parts.
And then to round it out, the most basic ever UI mockup for the sales page.
Fashion Genie
With this pipeline already built and proven, it was a quick jump to apply it to other mediums, which is why we decided to explore the same concept again but this time with a t-shirt.
How we made it
The general flow was the same: we made a core 2D video with the generated imagery and transitions, and we filmed a blank-shirt selfie with the script and general timing in mind. Fine tuning one to the other and using Snapchat’s inbuilt clothing tracking process we could easily apply the video as a texture that automatically camera + body tracked everything and masked the hand for us. Using these existing processes is a huge help because anyone who has manually rotoscoped these kinds of shots before knows how laborious it can be.
Honestly, the biggest learning with this shirt project was that it takes so much time to do “instant” generation with AI tools. We spent days and thousands of images, concepts, ideas, directions, attempts, img2img re-draws and so on to finally get towards the final assets.
There’s a sort of decision paralysis with the infinite canvas: because the art direction is done on the fly you’re constantly asking the AI for things and revising both the specific output (is this a good racoon holding pizza? is the hawaiian shirt right? is the pose right? etc.) and also finding yourself on these more macro paths: maybe the racoon looks like a penguin and suddenly you’re re-writing the whole concept to be penguin themed.



We were making zen gardens that looked like snakes, tie dye teddy bears, zebra prints that had faces in the stripes, swimmers in blue waves, mossy lichen on rocks, and so on.
Making the actual video ironically became the easiest and quickest part of this whole thing.